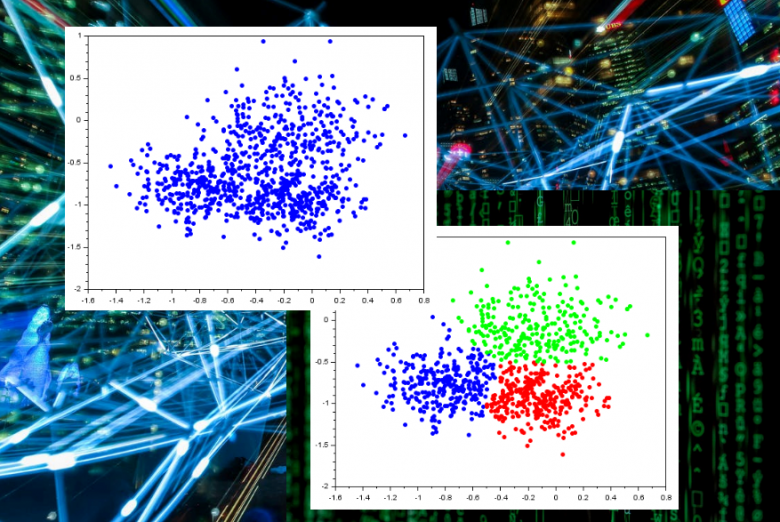
Peutz voert veelvuldig grote monitoringopdrachten uit, waarbij over een langere periode geluid- en/of trillingen gemeten worden. Dit resulteert in een enorme hoeveelheid data, afkomstig van verschillende bronnen. Het analyseren van deze data is vaak complex en tijdrovend. Maar wij halen met nieuwe machine-learning technieken meer informatie uit deze data dan met gangbare statistische of handmatige analyses mogelijk is. Met een clusteringalgoritme delen we de data in natuurlijke clusters in, waardoor we de statistiek per cluster inzichtelijk kunnen maken.
Groepeer de dominante geluidbronnen
Tijdens geluidmonitoring wordt alle data spectraal weggeschreven naar een database. Een algoritme zoekt in deze spectrale informatie naar geluidkarakteristieken die veel voorkomen. Deze verstoringen worden gegroepeerd in clusters en met behulp van steekproeven wordt eenvoudig bepaald welke geluidbron dominant is binnen het cluster. Dit kunnen bijvoorbeeld vrachtwagens, vliegtuigen, koelmachines, windmolens etc. zijn. Doordat het algoritme alle data die tot een specifieke geluidbron behoort groepeert, kan de relatieve bijdrage van deze geluidbron aan het optredende geluidniveau veel beter in kaart worden gebracht. Zo kan worden bepaald hoeveel procent van de tijd geluid ten gevolge van de specifieke geluidbron in de dag-, avond- en nachtperiode optreedt en wat de relatieve bijdrage per periode is.
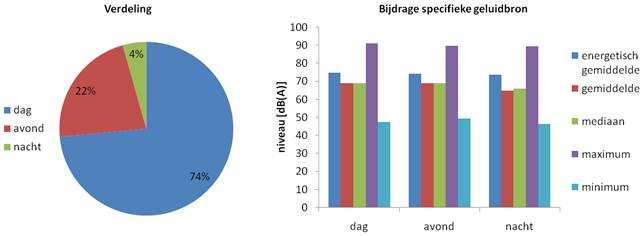
Algoritme bepaalt geluidniveau vrachtverkeer
In de onderstaande figuur is een visualisatie van de relatieve bijdrage van een specifieke geluidbron gegeven. Dit betreft een casus waarbij met behulp van een algoritme is bepaald wat de bijdrage van vrachtverkeer in het geluidniveau ter plaatse van een geprojecteerd hotel is. Hieruit kan worden geconcludeerd dat in de nachtperiode er vrijwel geen vrachtverkeer plaatsvindt, wat betekent dat er minder zware maatregelen wat betreft geluidwering noodzakelijk zijn.
 |
Door het gebruik van machine learning-algoritmes voor de analyse van monitoringdata halen we meer informatie uit data. Dit resulteert tot gedetailleerdere inzichten, waardoor meer gegronde beslissingen genomen kunnen worden met betrekking tot infrastructurele, industriële, bouwtechnische of milieutechnische vraagstukken. Bovendien kan het financiële besparingen opleveren, omdat extra voorzieningen achterwege kunnen blijven.
Heeft u vragen? Neem dan contact op met onze adviseurs. U vindt de contactgegevens van Robbert-Jan Dikken en Simon de Koning rechtsboven op deze pagina.